This image has stirred up a great deal of controversy and a bunch of people defending the state of software engineering.
I think y'all need a goddamn reality check, and I'm here to give it to you.
…and that's not a joke, it's how your design meetings should be starting.
A few days ago on Twitter someone asked a seemingly innocent question: "I'm writing a post on the failure of Stored Procedures as a platform. What, in your view, were the reasons they didn't work out?"
A lot of reasons were given: "They're hard to test" (They're not - your unit tests should be testing your database.), "They're not in git" (They should be - If they arent your revision control process is fucked because your database isn't controlled), "They're fundamentally unreadable and require exponentially more tacit knowledge aka are awful for new devs to understand" (They're not "fundamentally" anything, and if they're documented well any competent developer should be able to understand them), "They encourage silos where DBAs say no." (This is a people problem: Your process doesn't facilitate understanding between your DBAs and the rest of your team).
Some folks even came up with what I would argue are good reasons, like "Badly written stored procedures don't scale well" (which is true: If your stored procedures involve lots of processing overhead the DB server becomes a processing bottleneck, which is a Bad Thing), and "It's an additional moving part in the system" (generally something to avoid, unless that moving part is the simplest solution to a problem).
I was all set to have a friendly difference of opinion on this issue until I saw this blog post, which starts out great and quickly goes off the rails into the weeds and starts eating slugs with the DevOps "we don't need no stinkin' sysadmin/DBA" children.
So now you get a rant about why you still need a Developer, a Sysadmin, and a DBA.
Blocked waiting for my either the software development group to give me new code to test or my FreeBSD build VM to give me a new OS build to test, so how about some random thoughts on programming?
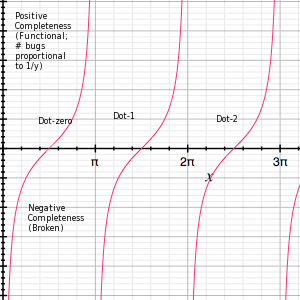
I've reached the inescapable conclusion that all software development cycles can be expressed as a single equation: y=tan(x+(π/2))
X represents time (on a totally non-linear scale) with each interval of width π being the development of a software release and the zero point where the function crosses the X axis representing the release of the X/πth version. The Y axis represents the state of the code - how "bug free" it is. I'll call the Y value within a version the "completeness" of the code for simplicity.
This functional model actually works surprisingly well:
During pre-0.0 release (X|0...π/2) the software is riddled with bugs and brokenness ("completeness" is negative - that shit don't work!).
At some point (X=(π+ε)/2) the software becomes at least functional (miniscule positive completeness), and is released to the unsuspecting public.
The initial release is buggy as shit, and massive patching and bug fixing happens
(This is roughly from X|(π+ε)/2...3π/2 -- For the sake of argument let's call the 3π/2 mark the .1 release, or in MS parlance, "Service Pack 1")
The software continues asymptotically approaching infinite completeness -- that nirvana state of having no bugs...
...At which point Marketing comes along and says the users want new features -- On our graph this corresponds to one of the vertical asymptote at multiples of π.
Development begins on the next (N/π)-dot-zero release, starting al over again from negative completeness.
In practical terms software development is not a true function: Each development window is independent and shifted toward X=0, with some overlap between the currently released version and the version under development.
 and Tics (little bloodsucking arachnids)")